Parallelism I: Inside the Core
|
|
|
- Lindsey Sharlene Cobb
- 5 years ago
- Views:
Transcription
1 Parallelism I: Inside the Core 1
2 The final Comprehensive Same general format as the Midterm. Review the homeworks, the slides, and the quizzes. 2
3 Key Points What is wide issue mean? How does does it affect performance? How does it affect pipeline design? What is the basic idea behind out-of-order execution? What is the difference between a true and false dependence? How do OOO processors remove false dependences? What is Simultaneous Multithreading? 3
4 Parallelism ET = IC * CPI * CT IC is more or less fixed We have shrunk cycle time as far as we can We have achieved a CPI of 1. Can we get faster? We can reduce our CPI to less than 1. The processor must do multiple operations at once. This is called Instruction Level Parallelism (ILP) 4


5 Approach 1: Widen the pipeline Process two instructions at once instead of 1 Often 1 odd PC instruction and 1 even PC This keeps the instruction fetch logic simpler. 2-wide, in-order, superscalar processor Potential problems? 5
 F D E M W Forwarding add $t1, $s3, $s3 F D D E M W 6")
6 Single issue refresher cycle 0 cycle 1 cycle 2 cycle 3 cycle 4 cycle 5 cycle 6 cycle 7 cycle 8 add $s1,$s2,$s3 F D E M W sub $s2,$s4,$s5 F D E M W Forwarding ld $s3, 0($s2) F D E M W Forwarding add $t1, $s3, $s3 F D D E M W 6
7 Dual issue: Ideal Case add $s1,$s2,$s3 F D E M W sub $s2,$s4,$s5 F D E M W ld $s3, 0($s2) F D E M W add $t1, $s3, $s3 F D E M W... F D E M W... F D E M W... F D E M W... F D E M W... F D E M W... F D E M W CPI == 0.5! 7
8 Dual issue: Structural Hazards Structural hazards We might not replicate everything Perhaps only one multiplier, one shifter, and one load/store unit What if the instruction is in the wrong place? If an upper instruction needs the lower pipeline, squash the lower instruction 8
9 Dual issue: dealing with hazards PC = 0 PC = 8 PC = 12 PC = add F D E M W sub F D E M W Mul F D E M W Shift F D E M W Shift F D E M W Ld F x x x x Shift x x x x x Ld F D E M W Shift moves to lower pipe load is squashed Load uses lower pipe Shift becomes a noop 9
10 Dual issue: Data Hazards The lower instruction may need a value produced by the upper instruction Forwarding cannot help us -- we must stall. 10
11 Dual issue: dealing with hazards Forwarding is essential! Both pipes stall add $s1, $s3,#4 F D E M W sub $s4, $s1, #4 F D D E M W add... F F D E M W sub... F F D E M W and... F D E M W or... F D E M W 11


12 Dual issue: Control Hazards The upper instruction might be branch. The lower instruction might be on the wrong path Solution 1: Require branches to execute in the lower pipeline -- See structural hazards. What about consecutive branches? -- Exercise for the reader What about branches to odd addresses? -- Squash the upper pipe 12
13 Beyond Dual Issue Wider pipelines are possible. There is often a separate floating point pipeline. Wide issue leads to hardware complexity Compiling gets harder, too. In practice, processors use of two options if they want more ILP Change the ISA and build a smart compiler: VLIW Keep the same ISA and build a smart processors: Out-of-order 16
14 23

15 Data dependences In general, if there is no dependence between two instructions, we can execute them in either order or simultaneously. But beware: Is there a dependence here? Can we reorder the instructions? Is the result the same? No! The final value of $t1 is different 24
16 False Dependence #1 Also called Write-after-Write dependences (WAW) occur when two instructions write to the same value The dependence is false because no data flows between the instructions -- They just produce an output with the same name. 25

17 Beware again! Is there a dependence here? Can we reorder the instructions? Is the result the same? No! The value in $s2 that 1 needs will be destroyed 26
18 False Dependence #2 This is a Write-after-Read (WAR) dependence Again, it is false because no data flows between the instructions 27
19 Out-of-Order Execution Any sequence of instructions has set of RAW, WAW, and WAR dependences that constrain its execution. Can we design a processor that extracts as much parallelism as possible, while still respecting these dependences? 28
20 The Central OOO Idea 1. Fetch a bunch of instructions 2. Build the dependence graph 3. Find all instructions with no unmet dependences 4. Execute them. 5. Repeat 29
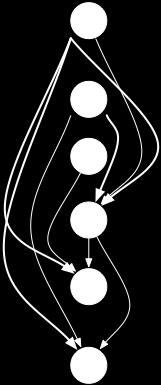


21 Example 8 Instructions in 5 cycles 30
22 Simplified OOO Pipeline A new schedule stage manages the Instruction Window The window holds the set of instruction the processor examines The fetch and decode fill the window Execute stage drains it Typically, OOO pipelines are also wide but it is not necessary. Impacts More forwarding, More stalls, longer branch resolution Fundamentally more work per instruction. 31
23 The Instruction Window The Instruction Window is the set of instruction the processor examines The fetch and decode fill the window Execute stage drains it The larger the window, the more parallelism the processor can find, but... Keeping the window filled is a challenge 32


24 The Issue Window 33


25 The Issue Window Schedule execute 34
26 Keeping the Window Filled Keeping the instruction window filled is key! Instruction windows are about 32 instructions (size is limited by their complexity, which is considerable) Branches are every 4-5 instructions. This means that the processor predict 6-8 consecutive branches correctly to keep the window full. On a mispredict, you flush the pipeline, which includes the emptying the window. 35
27 How Much Parallelism is There? Not much, in the presence of WAW and WAR dependences. These arise because we must reuse registers, and there are a limited number we can freely reuse. How can we get rid of them? 36
28 Removing False Dependences If WAW and WAR dependences arise because we have too few registers Let s add more! But! We can t! The Architecture only gives us 32 (why or why did we only use 5 bits?) Solution: Define a set of internal physical register that is as large as the number of instructions that can be in flight in a recent intel chip. Every instruction in the pipeline gets a registers Maintaining a register mapping table that determines which physical register currently holds the value for the required architectural registers. This is called Register Renaming 37
29 1: Add r3, r2, r3 2: Sub r2, r1, r3 3: Mult r1, r3, r1 4: Add r2, r3, r1 5: Add r2, r1, r3 Alpha 21264: Renaming Register map table r1 r2 r3 0: p1 p2 p3 1: : 3: 4: 5: 5 RAW WAW WAR
30 1: Add r3, r2, r3 2: Sub r2, r1, r3 3: Mult r1, r3, r1 4: Add r2, r3, r1 5: Add r2, r1, r RAW 4 Alpha 21264: Renaming 5 p1 currently holds the value of architectural registers r1 WAW WAR Register map table r1 r2 r3 0: p1 p2 p3 1: 2: 3: 4: 5:
31 Alpha 21264: Renaming 1: Add r3, r2, r3 2: Sub r2, r1, r3 3: Mult r1, r3, r1 4: Add r2, r3, r1 5: Add r2, r1, r3 p4, p2, p3 r1 r2 r3 0: p1 p2 p3 1: p1 p2 p : 3: 4: 5: 5 RAW WAW WAR
32 Alpha 21264: Renaming 1: Add r3, r2, r3 2: Sub r2, r1, r3 3: Mult r1, r3, r1 4: Add r2, r3, r1 5: Add r2, r1, r3 p4, p2, p3 p5, p1, p4 r1 r2 r3 0: p1 p2 p3 1: p1 p2 p : p1 p5 p4 3: 4: 5: 5 RAW WAW WAR
33 Alpha 21264: Renaming 1: Add r3, r2, r3 2: Sub r2, r1, r3 3: Mult r1, r3, r1 4: Add r2, r3, r1 5: Add r2, r1, r3 p4, p2, p3 p5, p1, p4 p6, p4, p1 r1 r2 r3 0: p1 p2 p3 1: p1 p2 p : p1 p5 p4 3: p6 p5 p4 4: 5: 5 RAW WAW WAR
34 Alpha 21264: Renaming 1: Add r3, r2, r3 2: Sub r2, r1, r3 3: Mult r1, r3, r1 4: Add r2, r3, r1 5: Add r2, r1, r3 p4, p2, p3 p5, p1, p4 p6, p4, p1 p7, p4, p6 r1 r2 r3 0: p1 p2 p3 1: p1 p2 p : p1 p5 p4 3: p6 p5 p4 4: p6 p7 p4 5: 5 RAW WAW WAR
35 Alpha 21264: Renaming 1: Add r3, r2, r3 2: Sub r2, r1, r3 3: Mult r1, r3, r1 4: Add r2, r3, r1 5: Add r2, r1, r3 p4, p2, p3 p5, p1, p4 p6, p4, p1 p7, p4, p6 p8, p6, p4 r1 r2 r3 0: p1 p2 p3 1: p1 p2 p : p1 p5 p4 3: p6 p5 p4 4: p6 p7 p4 5: p6 p8 p4 5 RAW WAW WAR
36 Alpha 21264: Renaming 1: Add r3, r2, r3 2: Sub r2, r1, r3 3: Mult r1, r3, r1 4: Add r2, r3, r1 5: Add r2, r1, r3 p4, p2, p3 p5, p1, p4 p6, p4, p1 p7, p4, p6 p8, p6, p4 r1 r2 r3 0: p1 p2 p3 1: p1 p2 p : p1 p5 p4 3: p6 p5 p4 4: p6 p7 p4 5: p6 p8 p4 RAW WAW WAR
37 New OOO Pipeline The register file is larger (to hold the physical registers) The pipeline is longer more forwarding Longer branch delay The payoff had better be significant (and it is) 46
38 Modern OOO Processors The fastest machines in the world are OOO superscalars AMD Barcelona 6-wide issue 106 instructions inflight at once. Intel Nehalem 5-way issue to 12 ALUs > 128 instructions in flight OOO provides the most benefit for memory operations. Non-dependent instructions can keep executing during cache misses. This is so-called memory-level parallelism. It is enormously important. CPU performance is (almost) all about memory performance nowadays (remember the memory wall graphs!) 47
39 48
40 49
41 50

42 0.8*1 + // non-memory 0.2* // memory (.9*1 // L1 hits + 0.1* // L1 misses (0.95*20 // L2 hits *100) // L2 misses 51
43 52
44 53
45 The Problem with OOO Even the fastest OOO machines only get about 1-2 IPC, even though they are 4-5 wide. Problems Insufficient ILP within applications per thread, usually Poor branch prediction performance Single threads also have little memory parallelism. Observation On many cycles, many ALUs and instruction queue slots sit empty 54


46 Simultaneous Multithreading AKA HyperThreading in Intel machines Run multiple threads at the same time Just throw all the instructions into the pipeline Keep some separate data for each Renaming table TLB entries PCs But the rest of the hardware is shared. It is surprisingly simple (but still quite complicated) 55
47 SMT Advantages Exploit the ILP of multiple threads at once Less dependence or branch prediction (fewer correct predictions required per thread) Less idle hardware (increased power efficiency) Much higher IPC -- up to 4 Disadvantages: threads can fight over resources and slow each other down. Historical footnote: Invented, in part, by our own Dean Tullsen when he was at UW 56
Lecture 14: Instruction Level Parallelism
 Lecture 14: Instruction Level Parallelism Last time Pipelining in the real world Today Control hazards Other pipelines Take QUIZ 10 over P&H 4.10-15, before 11:59pm today Homework 5 due Thursday March
Lecture 14: Instruction Level Parallelism Last time Pipelining in the real world Today Control hazards Other pipelines Take QUIZ 10 over P&H 4.10-15, before 11:59pm today Homework 5 due Thursday March
Computer Architecture: Out-of-Order Execution. Prof. Onur Mutlu (editted by Seth) Carnegie Mellon University
 Carnegie Mellon University") Computer Architecture: Out-of-Order Execution Prof. Onur Mutlu (editted by Seth) Carnegie Mellon University Reading for Today Smith and Sohi, The Microarchitecture of Superscalar Processors, Proceedings
Computer Architecture: Out-of-Order Execution Prof. Onur Mutlu (editted by Seth) Carnegie Mellon University Reading for Today Smith and Sohi, The Microarchitecture of Superscalar Processors, Proceedings
Advanced Superscalar Architectures. Speculative and Out-of-Order Execution
 6.823, L16--1 Advanced Superscalar Architectures Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 Speculative and Out-of-Order Execution Branch Prediction kill kill Branch
6.823, L16--1 Advanced Superscalar Architectures Asanovic Laboratory for Computer Science M.I.T. http://www.csg.lcs.mit.edu/6.823 Speculative and Out-of-Order Execution Branch Prediction kill kill Branch
Out-of-order Pipeline. Register Read. OOO execution (2-wide) OOO execution (2-wide) OOO execution (2-wide) OOO execution (2-wide)
 OOO execution (2-wide) OOO execution (2-wide) OOO execution (2-wide)") Out-of-order Pipeline Register Read When do instructions read the register file? Fetch Decode Rename Dispatch Buffer of instructions Issue Reg-read Execute Writeback Commit Option #: after select, right
Out-of-order Pipeline Register Read When do instructions read the register file? Fetch Decode Rename Dispatch Buffer of instructions Issue Reg-read Execute Writeback Commit Option #: after select, right
Lecture 20: Parallelism ILP to Multicores. James C. Hoe Department of ECE Carnegie Mellon University
 18 447 Lecture 20: Parallelism ILP to Multicores James C. Hoe Department of ECE Carnegie Mellon University 18 447 S18 L20 S1, James C. Hoe, CMU/ECE/CALCM, 2018 18 447 S18 L20 S2, James C. Hoe, CMU/ECE/CALCM,
18 447 Lecture 20: Parallelism ILP to Multicores James C. Hoe Department of ECE Carnegie Mellon University 18 447 S18 L20 S1, James C. Hoe, CMU/ECE/CALCM, 2018 18 447 S18 L20 S2, James C. Hoe, CMU/ECE/CALCM,
CIS 371 Computer Organization and Design
 CIS 371 Computer Organization and Design Unit 10: Static & Dynamic Scheduling Slides developed by Milo Martin & Amir Roth at the University of Pennsylvania with sources that included University of Wisconsin
CIS 371 Computer Organization and Design Unit 10: Static & Dynamic Scheduling Slides developed by Milo Martin & Amir Roth at the University of Pennsylvania with sources that included University of Wisconsin
Unit 9: Static & Dynamic Scheduling
 CIS 501: Computer Architecture Unit 9: Static & Dynamic Scheduling Slides originally developed by Drew Hilton, Amir Roth and Milo Mar;n at University of Pennsylvania CIS 501: Comp. Arch. Prof. Milo Martin
CIS 501: Computer Architecture Unit 9: Static & Dynamic Scheduling Slides originally developed by Drew Hilton, Amir Roth and Milo Mar;n at University of Pennsylvania CIS 501: Comp. Arch. Prof. Milo Martin
CIS 371 Computer Organization and Design
 CIS 371 Computer Organization and Design Unit 10: Static & Dynamic Scheduling Slides developed by M. Martin, A.Roth, C.J. Taylor and Benedict Brown at the University of Pennsylvania with sources that included
CIS 371 Computer Organization and Design Unit 10: Static & Dynamic Scheduling Slides developed by M. Martin, A.Roth, C.J. Taylor and Benedict Brown at the University of Pennsylvania with sources that included
Code Scheduling & Limitations
 This Unit: Static & Dynamic Scheduling CIS 371 Computer Organization and Design Unit 11: Static and Dynamic Scheduling App App App System software Mem CPU I/O Code scheduling To reduce pipeline stalls
This Unit: Static & Dynamic Scheduling CIS 371 Computer Organization and Design Unit 11: Static and Dynamic Scheduling App App App System software Mem CPU I/O Code scheduling To reduce pipeline stalls
Computer Architecture 计算机体系结构. Lecture 3. Instruction-Level Parallelism I 第三讲 指令级并行 I. Chao Li, PhD. 李超博士
 Computer Architecture 计算机体系结构 Lecture 3. Instruction-Level Parallelism I 第三讲 指令级并行 I Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review ISA, micro-architecture, physical design Evolution of ISA CISC vs
Computer Architecture 计算机体系结构 Lecture 3. Instruction-Level Parallelism I 第三讲 指令级并行 I Chao Li, PhD. 李超博士 SJTU-SE346, Spring 2018 Review ISA, micro-architecture, physical design Evolution of ISA CISC vs
DAT105: Computer Architecture Study Period 2, 2009 Exercise 2 Chapter 2: Instruction-Level Parallelism and Its Exploitation
 Study Period 2, 29 Exercise 2 Chapter 2: Instruction-Level Parallelism and Its Exploitation Mafijul Islam Department of Computer Science and Engineering November 12, 29 Study Period 2, 29 Goals: To understand
Study Period 2, 29 Exercise 2 Chapter 2: Instruction-Level Parallelism and Its Exploitation Mafijul Islam Department of Computer Science and Engineering November 12, 29 Study Period 2, 29 Goals: To understand
Computer Architecture ELE 475 / COS 475 Slide Deck 6: Superscalar 3. David Wentzlaff Department of Electrical Engineering Princeton University
 Computer Architecture ELE 475 / COS 475 Slide Deck 6: Superscalar 3 David Wentzlaff Department of Electrical Engineering Princeton University 1 Agenda SpeculaJon and Branches Register Renaming Memory DisambiguaJon
Computer Architecture ELE 475 / COS 475 Slide Deck 6: Superscalar 3 David Wentzlaff Department of Electrical Engineering Princeton University 1 Agenda SpeculaJon and Branches Register Renaming Memory DisambiguaJon
CIS 662: Sample midterm w solutions
 CIS 662: Sample midterm w solutions 1. (40 points) A processor has the following stages in its pipeline: IF ID ALU1 MEM1 MEM2 ALU2 WB. ALU1 stage is used for effective address calculation for loads, stores
CIS 662: Sample midterm w solutions 1. (40 points) A processor has the following stages in its pipeline: IF ID ALU1 MEM1 MEM2 ALU2 WB. ALU1 stage is used for effective address calculation for loads, stores
Announcements. Programming assignment #2 due Monday 9/24. Talk: Architectural Acceleration of Real Time Physics Glenn Reinman, UCLA CS
 Lipasti, artin, Roth, Shen, Smith, Sohi, Tyson, Vijaykumar GAS STATION Pipelining II Fall 2007 Prof. Thomas Wenisch http://www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Austin,
Lipasti, artin, Roth, Shen, Smith, Sohi, Tyson, Vijaykumar GAS STATION Pipelining II Fall 2007 Prof. Thomas Wenisch http://www.eecs.umich.edu/courses/eecs470 Slides developed in part by Profs. Austin,
Optimality of Tomasulo s Algorithm Luna, Dong Gang, Zhao
 Optimality of Tomasulo s Algorithm Luna, Dong Gang, Zhao Feb 28th, 2002 Our Questions about Tomasulo Questions about Tomasulo s Algorithm Is it optimal (can always produce the wisest instruction execution
Optimality of Tomasulo s Algorithm Luna, Dong Gang, Zhao Feb 28th, 2002 Our Questions about Tomasulo Questions about Tomasulo s Algorithm Is it optimal (can always produce the wisest instruction execution
COSC 6385 Computer Architecture. - Tomasulos Algorithm
 COSC 6385 Computer Architecture - Tomasulos Algorithm Fall 2008 Analyzing a short code-sequence DIV.D F0, F2, F4 ADD.D F6, F0, F8 S.D F6, 0(R1) SUB.D F8, F10, F14 MUL.D F6, F10, F8 1 Analyzing a short
COSC 6385 Computer Architecture - Tomasulos Algorithm Fall 2008 Analyzing a short code-sequence DIV.D F0, F2, F4 ADD.D F6, F0, F8 S.D F6, 0(R1) SUB.D F8, F10, F14 MUL.D F6, F10, F8 1 Analyzing a short
Tomasulo-Style Register Renaming
 Tomasulo-Style Register Renaming ldf f0,x(r1) allocate RS#4 map f0 to RS#4 mulf f4,f0, allocate RS#6 ready, copy value f0 not ready, copy tag Map Table f0 f4 RS#4 RS T V1 V2 T1 T2 4 REG[r1] 6 REG[] RS#4
Tomasulo-Style Register Renaming ldf f0,x(r1) allocate RS#4 map f0 to RS#4 mulf f4,f0, allocate RS#6 ready, copy value f0 not ready, copy tag Map Table f0 f4 RS#4 RS T V1 V2 T1 T2 4 REG[r1] 6 REG[] RS#4
To read more. CS 6354: Tomasulo. Intel Skylake. Scheduling. How can we reorder instructions? Without changing the answer.
 To read more CS 6354: Tomasulo 21 September 2016 This day s paper: Tomasulo, An Efficient Algorithm for Exploiting Multiple Arithmetic Units Supplementary readings: Hennessy and Patterson, Computer Architecture:
To read more CS 6354: Tomasulo 21 September 2016 This day s paper: Tomasulo, An Efficient Algorithm for Exploiting Multiple Arithmetic Units Supplementary readings: Hennessy and Patterson, Computer Architecture:
CS 6354: Tomasulo. 21 September 2016
 1 CS 6354: Tomasulo 21 September 2016 To read more 1 This day s paper: Tomasulo, An Efficient Algorithm for Exploiting Multiple Arithmetic Units Supplementary readings: Hennessy and Patterson, Computer
1 CS 6354: Tomasulo 21 September 2016 To read more 1 This day s paper: Tomasulo, An Efficient Algorithm for Exploiting Multiple Arithmetic Units Supplementary readings: Hennessy and Patterson, Computer
6.823 Computer System Architecture Prerequisite Self-Assessment Test Assigned Feb. 6, 2019 Due Feb 11, 2019
 6.823 Computer System Architecture Prerequisite Self-Assessment Test Assigned Feb. 6, 2019 Due Feb 11, 2019 http://csg.csail.mit.edu/6.823/ This self-assessment test is intended to help you determine your
6.823 Computer System Architecture Prerequisite Self-Assessment Test Assigned Feb. 6, 2019 Due Feb 11, 2019 http://csg.csail.mit.edu/6.823/ This self-assessment test is intended to help you determine your
CMU Introduction to Computer Architecture, Spring 2013 HW 3 Solutions: Microprogramming Wrap-up and Pipelining
 CMU 18-447 Introduction to Computer Architecture, Spring 2013 HW 3 Solutions: Microprogramming Wrap-up and Pipelining Instructor: Prof. Onur Mutlu TAs: Justin Meza, Yoongu Kim, Jason Lin 1 Adding the REP
CMU 18-447 Introduction to Computer Architecture, Spring 2013 HW 3 Solutions: Microprogramming Wrap-up and Pipelining Instructor: Prof. Onur Mutlu TAs: Justin Meza, Yoongu Kim, Jason Lin 1 Adding the REP
Pipelining A B C D. Readings: Example: Doing the laundry. Ann, Brian, Cathy, & Dave. each have one load of clothes to wash, dry, and fold
 Pipelining Readings: 4.5-4.8 Example: Doing the laundry Ann, Brian, Cathy, & Dave A B C D each have one load of clothes to wash, dry, and fold Washer takes 30 minutes Dryer takes 40 minutes Folder takes
Pipelining Readings: 4.5-4.8 Example: Doing the laundry Ann, Brian, Cathy, & Dave A B C D each have one load of clothes to wash, dry, and fold Washer takes 30 minutes Dryer takes 40 minutes Folder takes
Advanced Superscalar Architectures
 Advanced Suerscalar Architectures Krste Asanovic Laboratory for Comuter Science Massachusetts Institute of Technology Physical Register Renaming (single hysical register file: MIPS R10K, Alha 21264, Pentium-4)
Advanced Suerscalar Architectures Krste Asanovic Laboratory for Comuter Science Massachusetts Institute of Technology Physical Register Renaming (single hysical register file: MIPS R10K, Alha 21264, Pentium-4)
PIPELINING: BRANCH AND MULTICYCLE INSTRUCTIONS
 PIPELINING: BRANCH AND MULTICYCLE INSTRUCTIONS Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 1 submission
PIPELINING: BRANCH AND MULTICYCLE INSTRUCTIONS Mahdi Nazm Bojnordi Assistant Professor School of Computing University of Utah CS/ECE 6810: Computer Architecture Overview Announcement Homework 1 submission
Improving Performance: Pipelining!
 Iproving Perforance: Pipelining! Meory General registers Meory ID EXE MEM WB Instruction Fetch (includes PC increent) ID Instruction Decode + fetching values fro general purpose registers EXE EXEcute arithetic/logic
Iproving Perforance: Pipelining! Meory General registers Meory ID EXE MEM WB Instruction Fetch (includes PC increent) ID Instruction Decode + fetching values fro general purpose registers EXE EXEcute arithetic/logic
Decoupling Loads for Nano-Instruction Set Computers
 Decoupling Loads for Nano-Instruction Set Computers Ziqiang (Patrick) Huang, Andrew Hilton, Benjamin Lee Duke University {ziqiang.huang, andrew.hilton, benjamin.c.lee}@duke.edu ISCA-43, June 21, 2016 1
Decoupling Loads for Nano-Instruction Set Computers Ziqiang (Patrick) Huang, Andrew Hilton, Benjamin Lee Duke University {ziqiang.huang, andrew.hilton, benjamin.c.lee}@duke.edu ISCA-43, June 21, 2016 1
Chapter 3: Computer Organization Fundamentals. Oregon State University School of Electrical Engineering and Computer Science.
 Chapter 3: Computer Organization Fundamentals Prof. Ben Lee Oregon State University School of Electrical Engineering and Computer Science Chapter Goals Understand the organization of a computer system
Chapter 3: Computer Organization Fundamentals Prof. Ben Lee Oregon State University School of Electrical Engineering and Computer Science Chapter Goals Understand the organization of a computer system
ENGN1640: Design of Computing Systems Topic 05: Pipeline Processor Design
 ENGN64: Design of Computing Systems Topic 5: Pipeline Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
ENGN64: Design of Computing Systems Topic 5: Pipeline Processor Design Professor Sherief Reda http://scale.engin.brown.edu Electrical Sciences and Computer Engineering School of Engineering Brown University
Anne Bracy CS 3410 Computer Science Cornell University. [K. Bala, A. Bracy, S. McKee, E. Sirer, H. Weatherspoon]
![Anne Bracy CS 3410 Computer Science Cornell University. [K. Bala, A. Bracy, S. McKee, E. Sirer, H. Weatherspoon]](/thumbs/92/110265614.jpg "Anne Bracy CS 3410 Computer Science Cornell University. [K. Bala, A. Bracy, S. McKee, E. Sirer, H. Weatherspoon]") Anne Bracy CS 3410 Computer Science Cornell University [K. Bala, A. Bracy, S. McKee, E. Sirer, H. Weatherspoon] Prog. Mem PC +4 inst Reg. File 5 5 5 control ALU Data Mem Fetch Decode Execute Memory WB
Anne Bracy CS 3410 Computer Science Cornell University [K. Bala, A. Bracy, S. McKee, E. Sirer, H. Weatherspoon] Prog. Mem PC +4 inst Reg. File 5 5 5 control ALU Data Mem Fetch Decode Execute Memory WB
Multi Core Processing in VisionLab
 Multi Core Processing in Multi Core CPU Processing in 25 August 2014 Copyright 2001 2014 by Van de Loosdrecht Machine Vision BV All rights reserved jaap@vdlmv.nl Overview Introduction Demonstration Automatic
Multi Core Processing in Multi Core CPU Processing in 25 August 2014 Copyright 2001 2014 by Van de Loosdrecht Machine Vision BV All rights reserved jaap@vdlmv.nl Overview Introduction Demonstration Automatic
CS152: Computer Architecture and Engineering Introduction to Pipelining. October 22, 1997 Dave Patterson (http.cs.berkeley.
 CS152: Computer Architecture and Engineering Introduction to Pipelining October 22, 1997 Dave Patterson (http.cs.berkeley.edu/~patterson) lecture slides: http://www-inst.eecs.berkeley.edu/~cs152/ cs 152
CS152: Computer Architecture and Engineering Introduction to Pipelining October 22, 1997 Dave Patterson (http.cs.berkeley.edu/~patterson) lecture slides: http://www-inst.eecs.berkeley.edu/~cs152/ cs 152
CS 152 Computer Architecture and Engineering. Lecture 15 - Advanced Superscalars
 CS 152 Comuter Architecture and Engineering Lecture 15 - Advanced Suerscalars Krste Asanovic Electrical Engineering and Comuter Sciences University of California at Berkeley htt://www.eecs.berkeley.edu/~krste
CS 152 Comuter Architecture and Engineering Lecture 15 - Advanced Suerscalars Krste Asanovic Electrical Engineering and Comuter Sciences University of California at Berkeley htt://www.eecs.berkeley.edu/~krste
ABB June 19, Slide 1
 Dr Simon Round, Head of Technology Management, MATLAB Conference 2015, Bern Switzerland, 9 June 2015 A Decade of Efficiency Gains Leveraging modern development methods and the rising computational performance-price
Dr Simon Round, Head of Technology Management, MATLAB Conference 2015, Bern Switzerland, 9 June 2015 A Decade of Efficiency Gains Leveraging modern development methods and the rising computational performance-price
CMPEN 411 VLSI Digital Circuits Spring Lecture 20: Multiplier Design
 CMPEN 411 VLSI Digital Circuits Spring 2011 Lecture 20: Multiplier Design [Adapted from Rabaey s Digital Integrated Circuits, Second Edition, 2003 J. Rabaey, A. Chandrakasan, B. Nikolic] Sp11 CMPEN 411
CMPEN 411 VLSI Digital Circuits Spring 2011 Lecture 20: Multiplier Design [Adapted from Rabaey s Digital Integrated Circuits, Second Edition, 2003 J. Rabaey, A. Chandrakasan, B. Nikolic] Sp11 CMPEN 411
CS 152 Computer Architecture and Engineering. Lecture 14 - Advanced Superscalars
 CS 152 Comuter Architecture and Engineering Lecture 14 - Advanced Suerscalars Krste Asanovic Electrical Engineering and Comuter Sciences University of California at Berkeley htt://www.eecs.berkeley.edu/~krste
CS 152 Comuter Architecture and Engineering Lecture 14 - Advanced Suerscalars Krste Asanovic Electrical Engineering and Comuter Sciences University of California at Berkeley htt://www.eecs.berkeley.edu/~krste
ECE 552 / CPS 550 Advanced Computer Architecture I. Lecture 10 Instruction-Level Parallelism Part 3
 ECE 552 / CPS 550 Advanced Comuter Architecture I Lecture 10 Instruction-Level Parallelism Part 3 Benjamin Lee Electrical and Comuter Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall12.html
ECE 552 / CPS 550 Advanced Comuter Architecture I Lecture 10 Instruction-Level Parallelism Part 3 Benjamin Lee Electrical and Comuter Engineering Duke University www.duke.edu/~bcl15 www.duke.edu/~bcl15/class/class_ece252fall12.html
Hakim Weatherspoon CS 3410 Computer Science Cornell University
 Hakim Weatherspoon CS 3410 Computer Science Cornell University The slides are the product of many rounds of teaching CS 3410 by Professors Weatherspoon, Bala, Bracy, McKee, and Sirer. memory inst register
Hakim Weatherspoon CS 3410 Computer Science Cornell University The slides are the product of many rounds of teaching CS 3410 by Professors Weatherspoon, Bala, Bracy, McKee, and Sirer. memory inst register
ECE 550D Fundamentals of Computer Systems and Engineering. Fall 2017
 ECE 550D Fundamentals of Computer Systems and Engineering Fall 2017 Digital Arithmetic Prof. John Board Duke University Slides are derived from work by Profs. Tyler Bletch and Andrew Hilton (Duke) Last
ECE 550D Fundamentals of Computer Systems and Engineering Fall 2017 Digital Arithmetic Prof. John Board Duke University Slides are derived from work by Profs. Tyler Bletch and Andrew Hilton (Duke) Last
In-Place Associative Computing:
 In-Place Associative Computing: A New Concept in Processor Design 1 Page Abstract 3 What s Wrong with Existing Processors? 3 Introducing the Associative Processing Unit 5 The APU Edge 5 Overview of APU
In-Place Associative Computing: A New Concept in Processor Design 1 Page Abstract 3 What s Wrong with Existing Processors? 3 Introducing the Associative Processing Unit 5 The APU Edge 5 Overview of APU
Computer Architecture and Parallel Computing 并行结构与计算. Lecture 5 SuperScalar and Multithreading. Peng Liu
 Comuter Architecture and Parallel Comuting 并行结构与计算 Lecture 5 SuerScalar and Multithreading Peng Liu College of Info. Sci. & Elec. Eng. Zhejiang University liueng@zju.edu.cn Last time in Lecture 04 Register
Comuter Architecture and Parallel Comuting 并行结构与计算 Lecture 5 SuerScalar and Multithreading Peng Liu College of Info. Sci. & Elec. Eng. Zhejiang University liueng@zju.edu.cn Last time in Lecture 04 Register
Pipelined MIPS Datapath with Control Signals
 uction ess uction Rs [:26] (Opcode[5:]) [5:] ranch luor. Decoder Pipelined MIPS path with Signals luor Raddr at Five instruction sequence to be processed by pipeline: op [:26] rs [25:2] rt [2:6] rd [5:]
uction ess uction Rs [:26] (Opcode[5:]) [5:] ranch luor. Decoder Pipelined MIPS path with Signals luor Raddr at Five instruction sequence to be processed by pipeline: op [:26] rs [25:2] rt [2:6] rd [5:]
4.2 Friction. Some causes of friction
 4.2 Friction Friction is a force that resists motion. Friction is found everywhere in our world. You feel the effects of when you swim, ride in a car, walk, and even when you sit in a chair. Friction can
4.2 Friction Friction is a force that resists motion. Friction is found everywhere in our world. You feel the effects of when you swim, ride in a car, walk, and even when you sit in a chair. Friction can
THE TORQUE GENERATOR OF WILLIAM F. SKINNER
 THE TORQUE GENERATOR OF WILLIAM F. SKINNER IN 1939, WHICH WAS THE START OF WORLD WAR TWO, WILLIAM SKINNER OF MIAMI IN FLORIDA DEMONSTRATED HIS FIFTH-GENERATION SYSTEM WHICH WAS POWERED BY SPINNING WEIGHTS.
THE TORQUE GENERATOR OF WILLIAM F. SKINNER IN 1939, WHICH WAS THE START OF WORLD WAR TWO, WILLIAM SKINNER OF MIAMI IN FLORIDA DEMONSTRATED HIS FIFTH-GENERATION SYSTEM WHICH WAS POWERED BY SPINNING WEIGHTS.
Improving Memory System Performance with Energy-Efficient Value Speculation
 Improving Memory System Performance with Energy-Efficient Value Speculation Nana B. Sam and Min Burtscher Computer Systems Laboratory Cornell University Ithaca, NY 14853 {besema, burtscher}@csl.cornell.edu
Improving Memory System Performance with Energy-Efficient Value Speculation Nana B. Sam and Min Burtscher Computer Systems Laboratory Cornell University Ithaca, NY 14853 {besema, burtscher}@csl.cornell.edu
BASIC MECHATRONICS ENGINEERING
 MBEYA UNIVERSITY OF SCIENCE AND TECHNOLOGY Lecture Summary on BASIC MECHATRONICS ENGINEERING NTA - 4 Mechatronics Engineering 2016 Page 1 INTRODUCTION TO MECHATRONICS Mechatronics is the field of study
MBEYA UNIVERSITY OF SCIENCE AND TECHNOLOGY Lecture Summary on BASIC MECHATRONICS ENGINEERING NTA - 4 Mechatronics Engineering 2016 Page 1 INTRODUCTION TO MECHATRONICS Mechatronics is the field of study
Series and Parallel Networks
 Series and Parallel Networks Department of Physics & Astronomy Texas Christian University, Fort Worth, TX January 17, 2014 1 Introduction In this experiment you will examine the brightness of light bulbs
Series and Parallel Networks Department of Physics & Astronomy Texas Christian University, Fort Worth, TX January 17, 2014 1 Introduction In this experiment you will examine the brightness of light bulbs
Simple Gears and Transmission
 Simple Gears and Transmission Simple Gears and Transmission page: of 4 How can transmissions be designed so that they provide the force, speed and direction required and how efficient will the design be?
Simple Gears and Transmission Simple Gears and Transmission page: of 4 How can transmissions be designed so that they provide the force, speed and direction required and how efficient will the design be?
1.2 Flipping Ferraris
 1.2 Flipping Ferraris A Solidify Understanding Task When people first learn to drive, they are often told that the faster they are driving, the longer it will take to stop. So, when you re driving on the
1.2 Flipping Ferraris A Solidify Understanding Task When people first learn to drive, they are often told that the faster they are driving, the longer it will take to stop. So, when you re driving on the
Embedded system design for a multi variable input operations
 IOSR Journal of Engineering (IOSRJEN) ISSN: 2250-3021 Volume 2, Issue 8 (August 2012), PP 29-33 Embedded system design for a multi variable input operations Niranjan N. Parandkar, Abstract: - There are
IOSR Journal of Engineering (IOSRJEN) ISSN: 2250-3021 Volume 2, Issue 8 (August 2012), PP 29-33 Embedded system design for a multi variable input operations Niranjan N. Parandkar, Abstract: - There are
Topics on Compilers. Introduction to CGRA
 4541.775 Topics on Compilers Introduction to CGRA Spring 2011 Reconfigurable Architectures reconfigurable hardware (reconfigware) implement specific hardware structures dynamically and on demand high performance
4541.775 Topics on Compilers Introduction to CGRA Spring 2011 Reconfigurable Architectures reconfigurable hardware (reconfigware) implement specific hardware structures dynamically and on demand high performance
AIR BRAKES THIS SECTION IS FOR DRIVERS WHO DRIVE VEHICLES WITH AIR BRAKES
 Section 5 AIR BRAKES THIS SECTION IS FOR DRIVERS WHO DRIVE VEHICLES WITH AIR BRAKES AIR BRAKES/Section 5 SECTION 5: AIR BRAKES THIS SECTION COVERS Air Brake System Parts Dual Air Brake Systems Inspecting
Section 5 AIR BRAKES THIS SECTION IS FOR DRIVERS WHO DRIVE VEHICLES WITH AIR BRAKES AIR BRAKES/Section 5 SECTION 5: AIR BRAKES THIS SECTION COVERS Air Brake System Parts Dual Air Brake Systems Inspecting
Overcurrent protection
 Overcurrent protection This worksheet and all related files are licensed under the Creative Commons Attribution License, version 1.0. To view a copy of this license, visit http://creativecommons.org/licenses/by/1.0/,
Overcurrent protection This worksheet and all related files are licensed under the Creative Commons Attribution License, version 1.0. To view a copy of this license, visit http://creativecommons.org/licenses/by/1.0/,
CprE 281: Digital Logic
 CprE 28: Digital Logic Instructor: Alexander Stoytchev http://www.ece.iastate.edu/~alexs/classes/ Registers and Counters CprE 28: Digital Logic Iowa State University, Ames, IA Copyright Alexander Stoytchev
CprE 28: Digital Logic Instructor: Alexander Stoytchev http://www.ece.iastate.edu/~alexs/classes/ Registers and Counters CprE 28: Digital Logic Iowa State University, Ames, IA Copyright Alexander Stoytchev
Near-Optimal Precharging in High-Performance Nanoscale CMOS Caches
 Near-Optimal Precharging in High-Performance Nanoscale CMOS Caches Se-Hyun Yang and Babak Falsafi Computer Architecture Laboratory (CALCM) Carnegie Mellon University {sehyun, babak}@cmu.edu http://www.ece.cmu.edu/~powertap
Near-Optimal Precharging in High-Performance Nanoscale CMOS Caches Se-Hyun Yang and Babak Falsafi Computer Architecture Laboratory (CALCM) Carnegie Mellon University {sehyun, babak}@cmu.edu http://www.ece.cmu.edu/~powertap
New Features and Description
 1 2 New Features and Description Full Throttle Decoder Operation for Diesels It is often challenging to make a scale model preform like it has the mass of a 260,000lb locomotive pulling 5,000 tons or more!
1 2 New Features and Description Full Throttle Decoder Operation for Diesels It is often challenging to make a scale model preform like it has the mass of a 260,000lb locomotive pulling 5,000 tons or more!
CS 250! VLSI System Design
 CS 250! VLSI System Design Lecture 3 Timing 2014-9-4! Professor Jonathan Bachrach! slides by John Lazzaro TA: Colin Schmidt www-insteecsberkeleyedu/~cs250/ UC Regents Fall 2013/1014 UCB everything doesn
CS 250! VLSI System Design Lecture 3 Timing 2014-9-4! Professor Jonathan Bachrach! slides by John Lazzaro TA: Colin Schmidt www-insteecsberkeleyedu/~cs250/ UC Regents Fall 2013/1014 UCB everything doesn
Roehrig Engineering, Inc.
 Roehrig Engineering, Inc. Home Contact Us Roehrig News New Products Products Software Downloads Technical Info Forums What Is a Shock Dynamometer? by Paul Haney, Sept. 9, 2004 Racers are beginning to realize
Roehrig Engineering, Inc. Home Contact Us Roehrig News New Products Products Software Downloads Technical Info Forums What Is a Shock Dynamometer? by Paul Haney, Sept. 9, 2004 Racers are beginning to realize
The Car Tutorial Part 2 Creating a Racing Game for Unity
 The Car Tutorial Part 2 Creating a Racing Game for Unity Part 2: Tweaking the Car 3 Center of Mass 3 Suspension 5 Suspension range 6 Suspension damper 6 Drag Multiplier 6 Speed, turning and gears 8 Exporting
The Car Tutorial Part 2 Creating a Racing Game for Unity Part 2: Tweaking the Car 3 Center of Mass 3 Suspension 5 Suspension range 6 Suspension damper 6 Drag Multiplier 6 Speed, turning and gears 8 Exporting
CMPEN 411 VLSI Digital Circuits Spring Lecture 24: Peripheral Memory Circuits
 CMPEN 411 VLSI Digital Circuits Spring 2012 Lecture 24: Peripheral Memory Circuits [Adapted from Rabaey s Digital Integrated Circuits, Second Edition, 2003 J. Rabaey, A. Chandrakasan, B. Nikolic] Sp12
CMPEN 411 VLSI Digital Circuits Spring 2012 Lecture 24: Peripheral Memory Circuits [Adapted from Rabaey s Digital Integrated Circuits, Second Edition, 2003 J. Rabaey, A. Chandrakasan, B. Nikolic] Sp12
CHAPTER 19 DC Circuits Units
 CHAPTER 19 DC Circuits Units EMF and Terminal Voltage Resistors in Series and in Parallel Kirchhoff s Rules EMFs in Series and in Parallel; Charging a Battery Circuits Containing Capacitors in Series and
CHAPTER 19 DC Circuits Units EMF and Terminal Voltage Resistors in Series and in Parallel Kirchhoff s Rules EMFs in Series and in Parallel; Charging a Battery Circuits Containing Capacitors in Series and
INVESTIGATION ONE: WHAT DOES A VOLTMETER DO? How Are Values of Circuit Variables Measured?
 How Are Values of Circuit Variables Measured? INTRODUCTION People who use electric circuits for practical purposes often need to measure quantitative values of electric pressure difference and flow rate
How Are Values of Circuit Variables Measured? INTRODUCTION People who use electric circuits for practical purposes often need to measure quantitative values of electric pressure difference and flow rate
DRIVING. Robotic Cars. Questions: Do you like to drive? Why? / Why not? Read the article below and then answer the questions.
 Questions: Do you like to drive? Why? / Why not? Read the article below and then answer the questions. Robotic Cars The year is 2020, and it s 7:45 on a rainy Monday morning, and you are in your car and
Questions: Do you like to drive? Why? / Why not? Read the article below and then answer the questions. Robotic Cars The year is 2020, and it s 7:45 on a rainy Monday morning, and you are in your car and
Flexible Waveform Generation Accomplishes Safe Braking
 Flexible Waveform Generation Accomplishes Safe Braking Just as the antilock braking sytem (ABS) has become a critical safety feature in automotive vehicles, it perhaps is even more important in railway
Flexible Waveform Generation Accomplishes Safe Braking Just as the antilock braking sytem (ABS) has become a critical safety feature in automotive vehicles, it perhaps is even more important in railway
CSCI 510: Computer Architecture Written Assignment 2 Solutions
 CSCI 510: Computer Architecture Written Assignment 2 Solutions The following code does compution over two vectors. Consider different execution scenarios and provide the average number of cycles per iterion
CSCI 510: Computer Architecture Written Assignment 2 Solutions The following code does compution over two vectors. Consider different execution scenarios and provide the average number of cycles per iterion
SUPER CAPACITOR CHARGE CONTROLLER KIT
 TEACHING RESOURCES ABOUT THE CIRCUIT COMPONENT FACTSHEETS HOW TO SOLDER GUIDE POWER YOUR PROJECT WITH THIS SUPER CAPACITOR CHARGE CONTROLLER KIT Version 2.0 Teaching Resources Index of Sheets TEACHING
TEACHING RESOURCES ABOUT THE CIRCUIT COMPONENT FACTSHEETS HOW TO SOLDER GUIDE POWER YOUR PROJECT WITH THIS SUPER CAPACITOR CHARGE CONTROLLER KIT Version 2.0 Teaching Resources Index of Sheets TEACHING
Fixing the Hyperdrive: Maximizing Rendering Performance on NVIDIA GPUs
 Fixing the Hyperdrive: Maximizing Rendering Performance on NVIDIA GPUs Louis Bavoil, Principal Engineer Booth #223 - South Hall www.nvidia.com/gdc Full-Screen Pixel Shader SM TEX L2 DRAM CROP SM = Streaming
Fixing the Hyperdrive: Maximizing Rendering Performance on NVIDIA GPUs Louis Bavoil, Principal Engineer Booth #223 - South Hall www.nvidia.com/gdc Full-Screen Pixel Shader SM TEX L2 DRAM CROP SM = Streaming
CS 152 Computer Architecture and Engineering
 CS 152 Computer Architecture and Engineering Lecture 23 Synchronization 2006-11-16 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/ 1 Last Time:
CS 152 Computer Architecture and Engineering Lecture 23 Synchronization 2006-11-16 John Lazzaro (www.cs.berkeley.edu/~lazzaro) TAs: Udam Saini and Jue Sun www-inst.eecs.berkeley.edu/~cs152/ 1 Last Time:
Pretest Module 21 Units 1-4 AC Generators & Three-Phase Motors
 Pretest Module 21 Units 1-4 AC Generators & Three-Phase Motors 1. What are the two main parts of a three-phase motor? Stator and Rotor 2. Which part of a three-phase squirrel-cage induction motor is a
Pretest Module 21 Units 1-4 AC Generators & Three-Phase Motors 1. What are the two main parts of a three-phase motor? Stator and Rotor 2. Which part of a three-phase squirrel-cage induction motor is a
Drowsy Caches Simple Techniques for Reducing Leakage Power Krisztián Flautner Nam Sung Kim Steve Martin David Blaauw Trevor Mudge
 Drowsy Caches Simple Techniques for Reducing Leakage Power Krisztián Flautner Nam Sung Kim Steve Martin David Blaauw Trevor Mudge krisztian.flautner@arm.com kimns@eecs.umich.edu stevenmm@eecs.umich.edu
Drowsy Caches Simple Techniques for Reducing Leakage Power Krisztián Flautner Nam Sung Kim Steve Martin David Blaauw Trevor Mudge krisztian.flautner@arm.com kimns@eecs.umich.edu stevenmm@eecs.umich.edu
Electric Circuits. Lab. FCJJ 16 - Solar Hydrogen Science Kit. Next Generation Science Standards. Initial Prep Time. Lesson Time. Assembly Requirements
 Next Generation Science Standards NGSS Science and Engineering Practices: Asking questions and defining problems Developing and using models Planning and carrying out investigations Analyzing and interpreting
Next Generation Science Standards NGSS Science and Engineering Practices: Asking questions and defining problems Developing and using models Planning and carrying out investigations Analyzing and interpreting
INSTITUTO SUPERIOR TÉCNICO. Architectures for Embedded Computing
 UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 02
UNIVERSIDADE TÉCNICA DE LISBOA INSTITUTO SUPERIOR TÉCNICO Departamento de Engenharia Informática Architectures for Embedded Computing MEIC-A, MEIC-T, MERC Lecture Slides Version 3.0 - English Lecture 02
The seal of the century web tension control
 TENSIONING GEARING CAMMING Three techniques that can improve your automated packaging equipment performance What are 3 core motion techniques that can improve performance? Web Tension Control Proportional
TENSIONING GEARING CAMMING Three techniques that can improve your automated packaging equipment performance What are 3 core motion techniques that can improve performance? Web Tension Control Proportional
S1 Sequential. T56 Magnum. Sequential shifter. Contents and assembly instructions
 S1 Sequential Sequential shifter T56 Magnum Contents and assembly instructions Parts List Sequential shifter x1 Base plate x1 Base spacer x1 Drill Square x1 Shaft fitting x1 Square washer x1 8mm Aluminium
S1 Sequential Sequential shifter T56 Magnum Contents and assembly instructions Parts List Sequential shifter x1 Base plate x1 Base spacer x1 Drill Square x1 Shaft fitting x1 Square washer x1 8mm Aluminium
Troubleshooting Guide for Limoss Systems
 Troubleshooting Guide for Limoss Systems NOTE: Limoss is a manufacturer and importer of linear actuators (motors) hand controls, power supplies, and cables for motion furniture. They are quickly becoming
Troubleshooting Guide for Limoss Systems NOTE: Limoss is a manufacturer and importer of linear actuators (motors) hand controls, power supplies, and cables for motion furniture. They are quickly becoming
Simple Gears and Transmission
 Simple Gears and Transmission Contents How can transmissions be designed so that they provide the force, speed and direction required and how efficient will the design be? Initial Problem Statement 2 Narrative
Simple Gears and Transmission Contents How can transmissions be designed so that they provide the force, speed and direction required and how efficient will the design be? Initial Problem Statement 2 Narrative
VHDL (and verilog) allow complex hardware to be described in either single-segment style to two-segment style
 allow complex hardware to be described in either single-segment style to two-segment style") FFs and Registers In this lecture, we show how the process block is used to create FFs and registers Flip-flops (FFs) and registers are both derived using our standard data types, std_logic, std_logic_vector,
FFs and Registers In this lecture, we show how the process block is used to create FFs and registers Flip-flops (FFs) and registers are both derived using our standard data types, std_logic, std_logic_vector,
Standby Inverters. Written by Graham Gillett Friday, 23 April :35 - Last Updated Sunday, 25 April :54
 There has been a lot of hype recently about alternative energy sources, especially with the Eskom load shedding (long since forgotten but about to start again), but most people do not know the basics behind
There has been a lot of hype recently about alternative energy sources, especially with the Eskom load shedding (long since forgotten but about to start again), but most people do not know the basics behind
9 Locomotive Compensation
 Part 3 Section 9 Locomotive Compensation August 2008 9 Locomotive Compensation Introduction Traditionally, model locomotives have been built with a rigid chassis. Some builders looking for more realism
Part 3 Section 9 Locomotive Compensation August 2008 9 Locomotive Compensation Introduction Traditionally, model locomotives have been built with a rigid chassis. Some builders looking for more realism
Finite Element Based, FPGA-Implemented Electric Machine Model for Hardware-in-the-Loop (HIL) Simulation
 Simulation") Finite Element Based, FPGA-Implemented Electric Machine Model for Hardware-in-the-Loop (HIL) Simulation Leveraging Simulation for Hybrid and Electric Powertrain Design in the Automotive, Presentation Agenda
Finite Element Based, FPGA-Implemented Electric Machine Model for Hardware-in-the-Loop (HIL) Simulation Leveraging Simulation for Hybrid and Electric Powertrain Design in the Automotive, Presentation Agenda
LABORATORY 2 MEASUREMENTS IN RESISTIVE NETWORKS AND CIRCUIT LAWS
 LABORATORY 2 MEASUREMENTS IN RESISTIVE NETWORKS AND CIRCUIT LAWS The objective of this experiment is to provide working knowledge of the ammeter, voltmeter, and ohmmeter as well as their limitations in
LABORATORY 2 MEASUREMENTS IN RESISTIVE NETWORKS AND CIRCUIT LAWS The objective of this experiment is to provide working knowledge of the ammeter, voltmeter, and ohmmeter as well as their limitations in
Direct-Mapped Cache Terminology. Caching Terminology. TIO Dan s great cache mnemonic. UCB CS61C : Machine Structures
 Lecturer SOE Dan Garcia inst.eecs.berkeley.edu/~cs61c UCB CS61C : Machine Structures Lecture 31 Caches II 2008-04-12 HP has begun testing research prototypes of a novel non-volatile memory element, the
Lecturer SOE Dan Garcia inst.eecs.berkeley.edu/~cs61c UCB CS61C : Machine Structures Lecture 31 Caches II 2008-04-12 HP has begun testing research prototypes of a novel non-volatile memory element, the
Chapter 5 Vehicle Operation Basics
 Chapter 5 Vehicle Operation Basics 5-1 STARTING THE ENGINE AND ENGAGING THE TRANSMISSION A. In the spaces provided, identify each of the following gears. AUTOMATIC TRANSMISSION B. Indicate the word or
Chapter 5 Vehicle Operation Basics 5-1 STARTING THE ENGINE AND ENGAGING THE TRANSMISSION A. In the spaces provided, identify each of the following gears. AUTOMATIC TRANSMISSION B. Indicate the word or
LLTek Introduces PowerBox Chip-Tuning Technology
 LLTek Introduces PowerBox Chip-Tuning Technology Fast Do it Yourself Installation With Stealth Technology Applications: for gas turbo or supercharged cars for diesel, turbo diesel or supercharged diesel
LLTek Introduces PowerBox Chip-Tuning Technology Fast Do it Yourself Installation With Stealth Technology Applications: for gas turbo or supercharged cars for diesel, turbo diesel or supercharged diesel
DYNAMIC BOOST TM 1 BATTERY CHARGING A New System That Delivers Both Fast Charging & Minimal Risk of Overcharge
 DYNAMIC BOOST TM 1 BATTERY CHARGING A New System That Delivers Both Fast Charging & Minimal Risk of Overcharge William Kaewert, President & CTO SENS Stored Energy Systems Longmont, Colorado Introduction
DYNAMIC BOOST TM 1 BATTERY CHARGING A New System That Delivers Both Fast Charging & Minimal Risk of Overcharge William Kaewert, President & CTO SENS Stored Energy Systems Longmont, Colorado Introduction
Pipeline Hazards. See P&H Chapter 4.7. Hakim Weatherspoon CS 3410, Spring 2013 Computer Science Cornell University
 Pipeline Hazards See P&H Chapter 4.7 Hakim Weatherspoon CS 341, Spring 213 Computer Science Cornell niversity Goals for Today Data Hazards Revisit Pipelined Processors Data dependencies Problem, detection,
Pipeline Hazards See P&H Chapter 4.7 Hakim Weatherspoon CS 341, Spring 213 Computer Science Cornell niversity Goals for Today Data Hazards Revisit Pipelined Processors Data dependencies Problem, detection,
Digital Command & Control (DCC) has progressed a great deal over recent years and can now provide a myriad of actions which can be made to precisely r
 has progressed a great deal over recent years and can now provide a myriad of actions which can be made to precisely r") (Digital Command & Control) January 2016 All content & images copyright of Garden Railways Specialists Ltd Digital Command & Control (DCC) has progressed a great deal over recent years and can now provide
(Digital Command & Control) January 2016 All content & images copyright of Garden Railways Specialists Ltd Digital Command & Control (DCC) has progressed a great deal over recent years and can now provide
FLEET SAFETY. Drive to the conditions
 FLEET SAFETY Drive to the conditions Welcome Welcome to Fleet Safety training. This module examines driving at an appropriate speed, known as driving to the conditions. This module will take 10 minutes
FLEET SAFETY Drive to the conditions Welcome Welcome to Fleet Safety training. This module examines driving at an appropriate speed, known as driving to the conditions. This module will take 10 minutes
Abstract. Executive Summary. Emily Rogers Jean Wang ORF 467 Final Report-Middlesex County
 Emily Rogers Jean Wang ORF 467 Final Report-Middlesex County Abstract The purpose of this investigation is to model the demand for an ataxi system in Middlesex County. Given transportation statistics for
Emily Rogers Jean Wang ORF 467 Final Report-Middlesex County Abstract The purpose of this investigation is to model the demand for an ataxi system in Middlesex County. Given transportation statistics for
Balancing the Wheels on a Bench Grinder, version 2
 Balancing the Wheels on a Bench Grinder, version 2 By R. G. Sparber Copyleft protects this document. 1 I recently replaced the wheels on my bench grinder and the vibration was horrible. With a lot of help
Balancing the Wheels on a Bench Grinder, version 2 By R. G. Sparber Copyleft protects this document. 1 I recently replaced the wheels on my bench grinder and the vibration was horrible. With a lot of help
How to use the Multirotor Motor Performance Data Charts
 How to use the Multirotor Motor Performance Data Charts Here at Innov8tive Designs, we spend a lot of time testing all of the motors that we sell, and collect a large amount of data with a variety of propellers.
How to use the Multirotor Motor Performance Data Charts Here at Innov8tive Designs, we spend a lot of time testing all of the motors that we sell, and collect a large amount of data with a variety of propellers.
PORSCHE V r Valve Timing Instructions. Copyright 2009 Written by Mike Frye Edited my Adam G.
 PORSCHE 928 32V r Valve Timing Instructions Copyright 2009 Written by Mike Frye Edited my Adam G. Sections: Overview.3 Disclaimer/warnings/things to watch for 4 Terms and naming conventions used in this
PORSCHE 928 32V r Valve Timing Instructions Copyright 2009 Written by Mike Frye Edited my Adam G. Sections: Overview.3 Disclaimer/warnings/things to watch for 4 Terms and naming conventions used in this
Fault Attacks Made Easy: Differential Fault Analysis Automation on Assembly Code
 Fault Attacks Made Easy: Differential Fault Analysis Automation on Assembly Code Jakub Breier, Xiaolu Hou and Yang Liu 10 September 2018 1 / 25 Table of Contents 1 Background and Motivation 2 Overview
Fault Attacks Made Easy: Differential Fault Analysis Automation on Assembly Code Jakub Breier, Xiaolu Hou and Yang Liu 10 September 2018 1 / 25 Table of Contents 1 Background and Motivation 2 Overview
Speakers and Motors. Three feet of magnet wire to make a coil (you can reuse any of the coils you made in the last lesson if you wish)
") Speakers and Motors We ve come a long way with this magnetism thing and hopefully you re feeling pretty good about how magnetism works and what it does. This lesson, we re going to use what we ve learned
Speakers and Motors We ve come a long way with this magnetism thing and hopefully you re feeling pretty good about how magnetism works and what it does. This lesson, we re going to use what we ve learned
Atlas ESR and ESR + Equivalent Series Resistance and Capacitance Meter. Model ESR60/ESR70. Designed and manufactured with pride in the UK.
 GB60/70-9 Atlas ESR and ESR + Equivalent Series Resistance and Capacitance Meter Model ESR60/ESR70 Designed and manufactured with pride in the UK User Guide Peak Electronic Design Limited 2004/2016 In
GB60/70-9 Atlas ESR and ESR + Equivalent Series Resistance and Capacitance Meter Model ESR60/ESR70 Designed and manufactured with pride in the UK User Guide Peak Electronic Design Limited 2004/2016 In
Physics 144 Chowdary How Things Work. Lab #5: Circuits
 Physics 144 Chowdary How Things Work Spring 2006 Name: Partners Name(s): Lab #5: Circuits Introduction In today s lab, we ll learn about simple electric circuits. All electrical and electronic appliances
Physics 144 Chowdary How Things Work Spring 2006 Name: Partners Name(s): Lab #5: Circuits Introduction In today s lab, we ll learn about simple electric circuits. All electrical and electronic appliances
EECS 583 Class 9 Classic Optimization
 EECS 583 Class 9 Classic Optimization University of Michigan September 28, 2016 Generalizing Dataflow Analysis Transfer function» How information is changed by something (BB)» OUT = GEN + (IN KILL) /*
EECS 583 Class 9 Classic Optimization University of Michigan September 28, 2016 Generalizing Dataflow Analysis Transfer function» How information is changed by something (BB)» OUT = GEN + (IN KILL) /*
FLYING CAR NANODEGREE SYLLABUS
 FLYING CAR NANODEGREE SYLLABUS Term 1: Aerial Robotics 2 Course 1: Introduction 2 Course 2: Planning 2 Course 3: Control 3 Course 4: Estimation 3 Term 2: Intelligent Air Systems 4 Course 5: Flying Cars
FLYING CAR NANODEGREE SYLLABUS Term 1: Aerial Robotics 2 Course 1: Introduction 2 Course 2: Planning 2 Course 3: Control 3 Course 4: Estimation 3 Term 2: Intelligent Air Systems 4 Course 5: Flying Cars
GRID CONSTRAINT: OPTIONS FOR PROJECT DEVELOPMENT
 GRID CONSTRAINT: OPTIONS FOR PROJECT DEVELOPMENT 2 What s the Problem? Constrained grid is an issue that impacts many new renewables developments. A quick look at the distribution heat maps published by
GRID CONSTRAINT: OPTIONS FOR PROJECT DEVELOPMENT 2 What s the Problem? Constrained grid is an issue that impacts many new renewables developments. A quick look at the distribution heat maps published by
Volumetric Efficiency Diagnostics by Glen Beanard - Dec 29,
 Volumetric Efficiency Diagnostics by Glen Beanard - Dec 29, 2014 1 7047 http://www.underhoodservice.com/volumetric-efficiency-diagnostics/ A few years ago, I obtained an OBDII scan tool/dynamometer simulation/calculation
Volumetric Efficiency Diagnostics by Glen Beanard - Dec 29, 2014 1 7047 http://www.underhoodservice.com/volumetric-efficiency-diagnostics/ A few years ago, I obtained an OBDII scan tool/dynamometer simulation/calculation
TL4076 Top 5 Tips Get to know your TL4076
 TL4076 Top 5 Tips Get to know your TL4076 Thermal Break with Teflon liner (behind fan) Hot End Assembly Fan Heat Block Extruder with toothed gear(brass) and idler (steel) Filament Guide Tube Nozzle Cable
TL4076 Top 5 Tips Get to know your TL4076 Thermal Break with Teflon liner (behind fan) Hot End Assembly Fan Heat Block Extruder with toothed gear(brass) and idler (steel) Filament Guide Tube Nozzle Cable